Payload CMS: Getting Started Using the New Join Field
Posted on: August 11 2025

Payload CMS has just rolled out an exciting feature that takes content relationships to a whole new level—the Join field. This new field type allows you to link data seamlessly, making it easier to organize and retrieve related content.
In this guide, we'll walk you through how to set up and use the Join field in Payload CMS, allowing you to create more flexible two-way content queries.
In this article, I'll be covering:
- What is the new Join field?
- How it can improve content management.
- How to use it in a realistic example.
- When to use the Join field.
- Querying Join fields with REST and GraphQL
Let’s dive in to see how this simple yet powerful feature can enhance your content relationships!
What is the Payload CMS Join field?
The Join fields is a new field type provided since Payload 3.0 and can be used to create bi-directional Collection relationships.
The following Collection relationship fields are available:
Using the join field type will allow for two-way query support on an adjoining Collection.
How does the Join field improve content management?
The relationship field is probably all you'll need in most cases, since queries can be written using where conditions on the related Collection.
For example, if we have a Posts Collection with a relationship to a Categories Collection, there is only a one-way query relationship.

However, when a join field is added on the Categories Collection, it creates a two-way query relationship.

Using the join field will now link the two Collections together and provide the following query changes:
- Querying Posts will now include any join field data to Categories.
- Querying Categories will now include any related Posts data defined by the join field.
Use cases for the Join field
The join field opens up some possibilities for uses cases like:
- More visibility in the Admin UI to show full relationship data.
- Pages and components might need the adjoining Collection data to build things like links, menus from the adjoining Collection.
- When it's easier to use a single query versus multiple queries.
There are so many use cases and you're likely to run into a design situation that might benefit from a join relationship.
Payload CMS has great support for both relationship and join fields in the Admin UI to create really powerful back office content management solutions.
Building a realistic example using Join
So now, let's build a practical example to really see how the join field can be used. We'll also take a look at the query options when using the join field.
The Actors and Movies use case
Here's a couple Collection configurations that will define a join relationship between:
- Movies: Defines the relationship field to Actors and acts as the owning side since it's declaring the relationship.
- Actors: Defines the join field back to the actors field in the Movies Collection.
The Movies Collection defines relationship fields to hold the movie details.
Movies Collection with relationship
import type { CollectionConfig } from 'payload'
export const Movies: CollectionConfig = {
slug: 'movies',
admin: {
useAsTitle: 'name',
},
access: {
read: () => true,
},
fields: [
{
name: 'name',
label: 'Name',
type: 'text',
required: true,
},
{
name: 'year',
label: 'Year',
type: 'number',
},
{
name: 'runtime',
label: 'Runtime',
type: 'number',
},
{
name: 'releaseDate',
label: 'Release Date',
type: 'text',
},
{
name: 'actors',
type: 'relationship',
relationTo: 'actors',
hasMany: true,
},
{
name: 'storyline',
label: 'Storyline',
type: 'text',
},
],
}
The Actors Collection defines relationship fields to hold details for an actor.
Actors Collection with join
import type { CollectionConfig } from 'payload'
export const Actors: CollectionConfig = {
slug: 'actors',
admin: {
useAsTitle: 'name',
},
access: {
read: () => true,
},
fields: [
{
name: 'name',
label: 'Name',
type: 'text',
},
{
name: 'birthname',
label: 'BirthnName',
type: 'text',
},
{
name: 'birtdate',
label: 'Birth date',
type: 'text',
},
{
name: 'birthplace',
label: 'Birth place',
type: 'text',
},
{
name: 'movies',
type: 'join',
collection: 'movies',
on: 'actors'
},
],
}
Analyzing the Actors Join field
Let's analyze the actual join field notation.
Analyzing the join field
{
name: 'movies',
type: 'join',
collection: 'movies',
on: 'actors'
},
Here's what each field is doing.
- name: Name of the field in the Actors Collection.
- type: Declares the type to be a join.
- collection: Points back to the Movies collection.
- on: Defines which field in the Movies collection to create the join on, in this case it's the actors field which defined the adjoining relationship.
Managing relationships in the Admin UI
After seeding some movie and actor data in the database, we can see how the Admin UI forms will look populated with data.
One of the standout features is the manageability of the relationship and join fields in the Admin UI.
Movie Collection admin pages
The listing page for movies is pretty standard since it's a relationship field type.
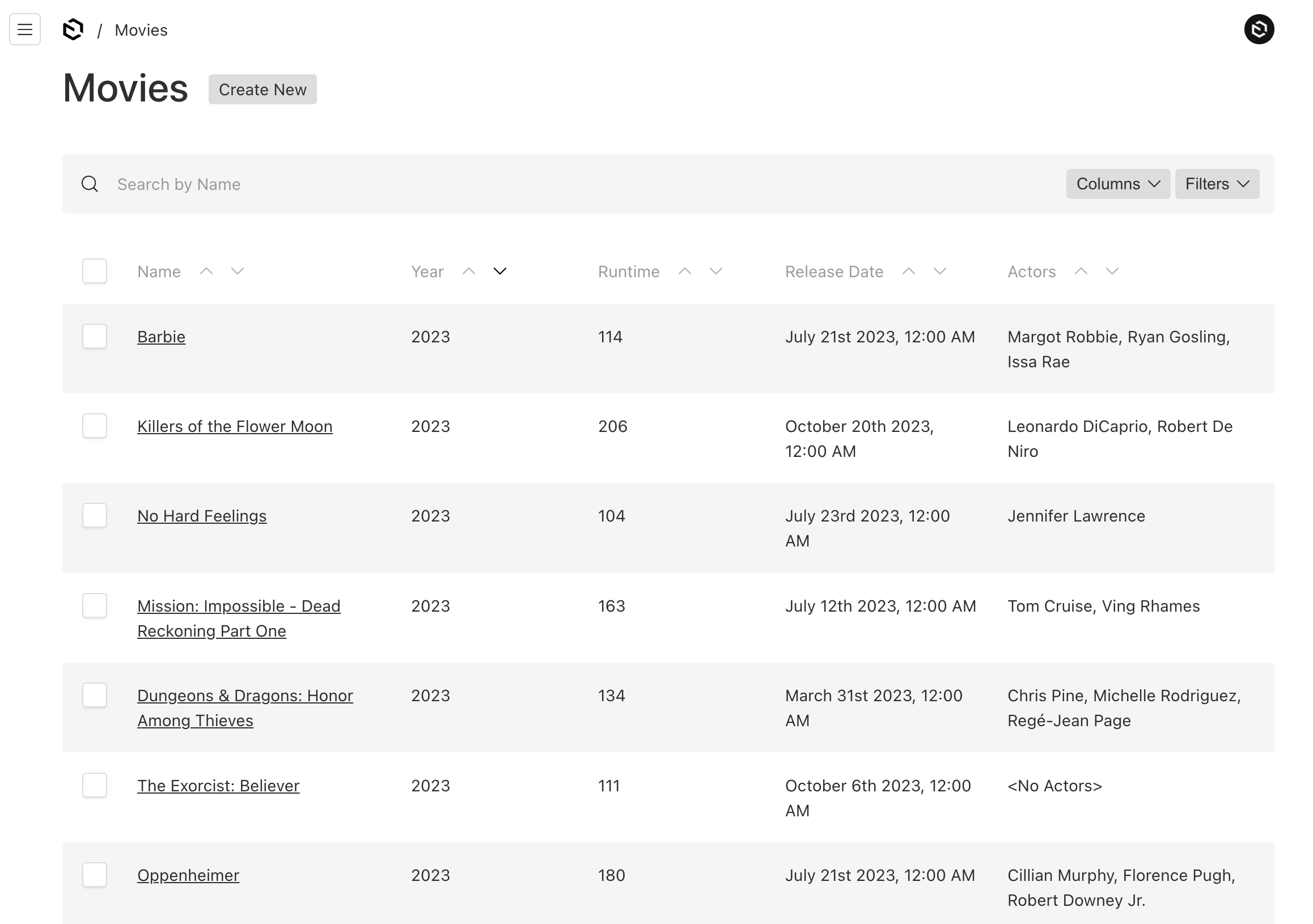
The movie details fields shows the actors associated with each movie.
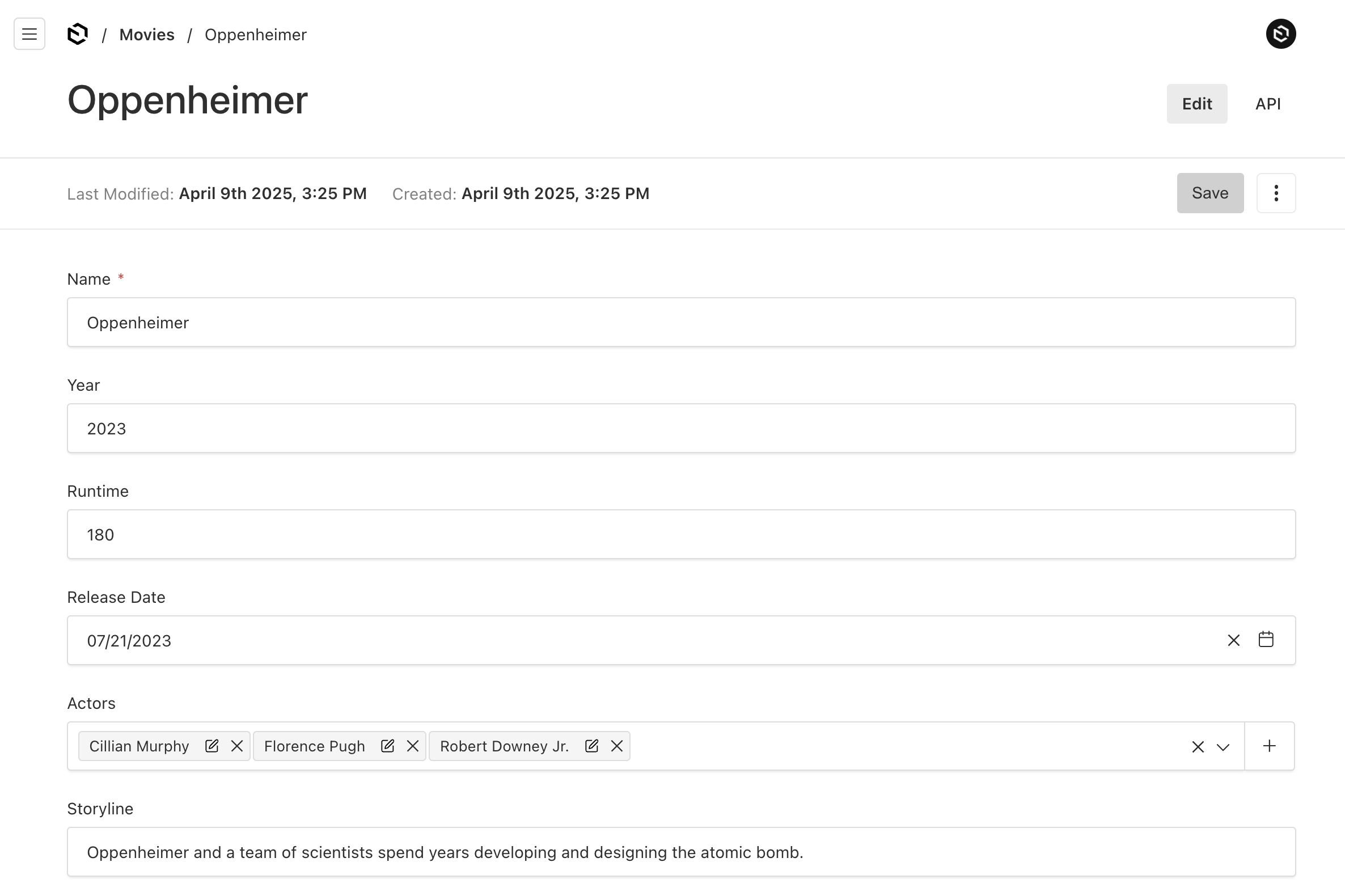
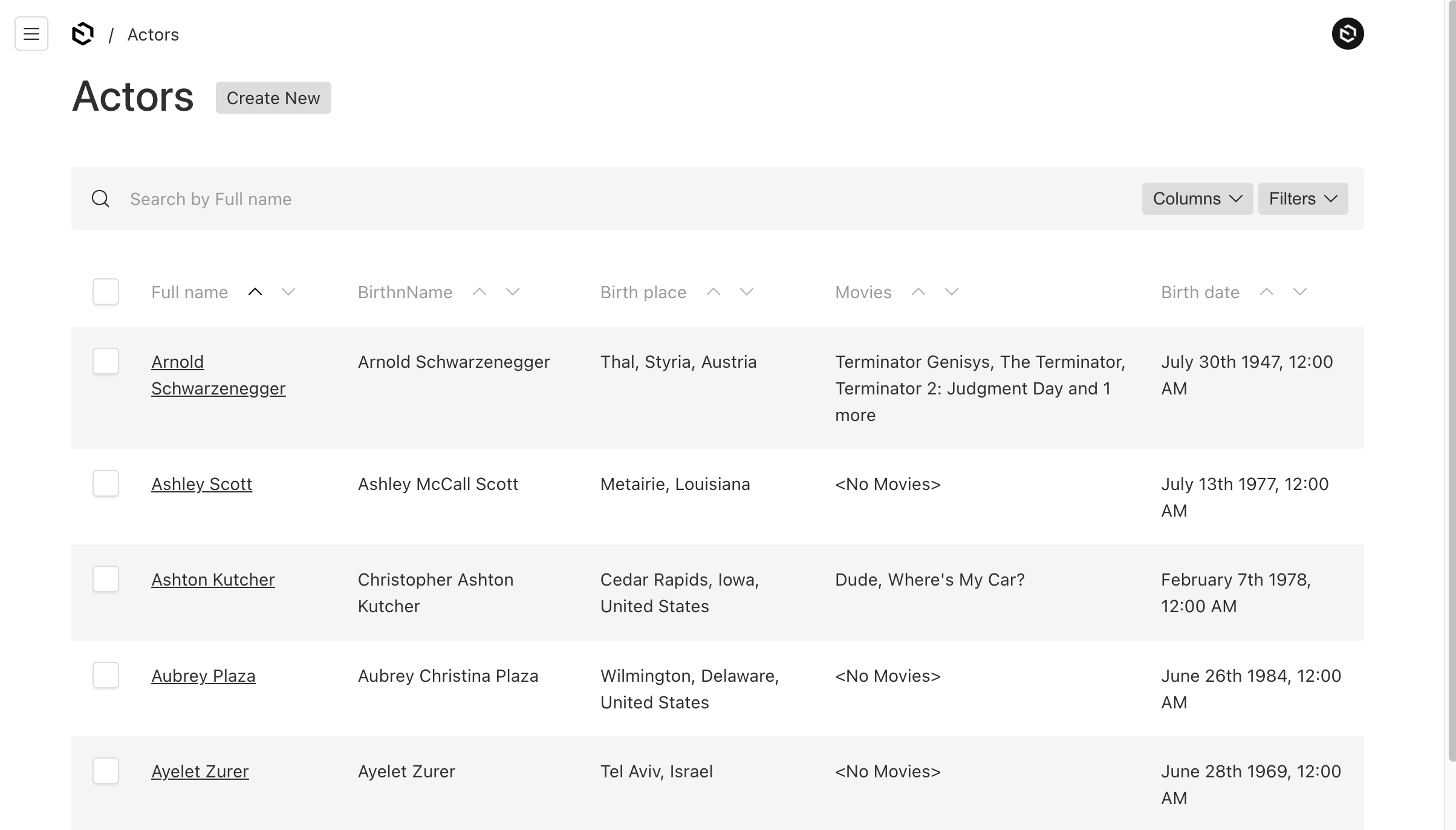
Actor Admin pages
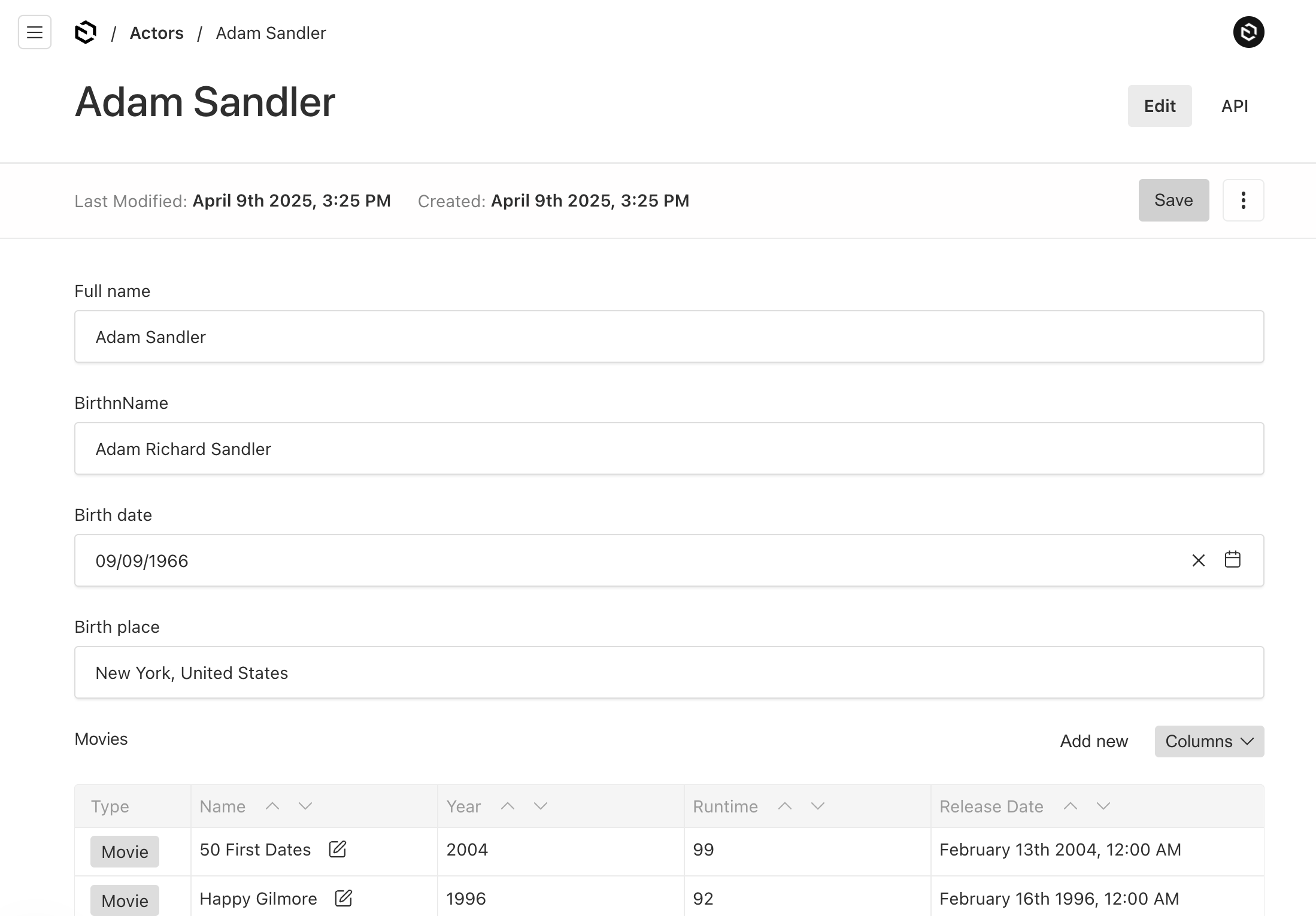
The listing page of actors, shows the movies they are associated with if available.
The details page for each actor also shows the associated movies in a table view.
Editing Join fields
One thing to note is that the field that defines the relationship is owning side and is where related documents are created, updated and removed.
The join side is there to provide the related data in the Admin UI and in queries and does not manage the relationship.
Querying on Join fields
Let's take a look at running some queries using the REST approach and then a GraphQL alternative.
Movie query using REST
This query will make a basic REST call to the movies endpoint, with following query parameters.
- [where][name][equals]=Happy Gilmore
- limit=1
- depth=1
Query movies with where clause
http://localhost:3000/api/movies?[where][name][equals]=Happy Gilmore&limit=1&depth=1
I'll hide the pagination meta information since the limit will only return one movie document.
Response:
Movies query response
{
"docs": [
{
"createdAt": "2025-04-09T22:25:56.656Z",
"updatedAt": "2025-04-09T22:25:56.656Z",
"name": "Happy Gilmore",
"year": 1996,
"runtime": 92,
"releaseDate": "1996-02-16T08:00:00.000Z",
"actors": [
{
"createdAt": "2025-04-09T22:25:56.530Z",
"updatedAt": "2025-04-09T22:25:56.530Z",
"name": "Adam Sandler",
"birthname": "Adam Richard Sandler",
"birthdate": "1966-09-09T07:00:00.000Z",
"birthplace": "New York, United States",
"movies": {
"docs": [
"67f6f3f4dde9aad96973917d",
"67f6f3f4dde9aad969739142"
],
"hasNextPage": false
},
"id": "67f6f3f4dde9aad969738e68"
}
],
"storyline": " A rejected hockey player puts his skills to the golf course to save his grandmother's house.",
"id": "67f6f3f4dde9aad969739142"
}
]
}
This is mostly a typical relationship query response with one exception:
- The nested actors.movies path.
The join on the Actors Collection is loading each actors.movies list as well.
Each nested join field will provide the inverse adjoining data using the pagination format PaginatedDocs type which contains the docs: [...] and pagination format.
Actors query using REST
Here's the REST call to the actors endpoint with the following query params.
- [where][name][equals]=Adam Sandler
- limit=1
- depth=1
Query actors with where clause
http://localhost:3000/api/actors?[where][name][equals]=Adam Sandler&limit=1&depth=1
Response:
Actors query response
{
"docs": [
{
"createdAt": "2025-04-09T22:25:56.530Z",
"updatedAt": "2025-04-09T22:25:56.530Z",
"name": "Adam Sandler",
"birthname": "Adam Richard Sandler",
"birthdate": "1966-09-09T07:00:00.000Z",
"birthplace": "New York, United States",
"movies": {
"docs": [
{
"createdAt": "2025-04-09T22:25:56.657Z",
"updatedAt": "2025-04-09T22:25:56.657Z",
"name": "50 First Dates",
"year": 2004,
"runtime": 99,
"releaseDate": "2004-02-13T08:00:00.000Z",
"actors": [
"67f6f3f4dde9aad969738e68"
],
"storyline": "",
"id": "67f6f3f4dde9aad96973917d"
},
{
"createdAt": "2025-04-09T22:25:56.656Z",
"updatedAt": "2025-04-09T22:25:56.656Z",
"name": "Happy Gilmore",
"year": 1996,
"runtime": 92,
"releaseDate": "1996-02-16T08:00:00.000Z",
"actors": [
"67f6f3f4dde9aad969738e68"
],
"storyline": " A rejected hockey player puts his skills to the golf course to save his grandmother's house.",
"id": "67f6f3f4dde9aad969739142"
}
],
"hasNextPage": false
},
"id": "67f6f3f4dde9aad969738e68"
}
]
}
Since the Actors Collection has a join, it's now returning the inverse movies data as well. This is why the join is such a powerful feature in Payload CMS.
However, this extra nested array is most likely unneeded since the movies array is what we're really after.
The depth of the problem
Using REST is going to be the easiest solution in most cases but when using join fields, things can add up pretty quickly even with a depth of 1.
Consider cases where you might have nested layout blocks with references to the Movies or Actors Collections or even returning a higher limit count.
Since the REST query approach simply goes by a depth indicator to regulate how much to load, you'll need to resort to GraphQL to streamline and fine tune the responses.
Querying on Join fields with GraphQL
Let's take a look at the previous queries but use GraphQL instead.
Movies query with GraphQL
Using the generated schema.graphql in Payload we can build a query using the Movies query and just select the fields we want in the docs section as follows.
Movies query using GraphQL
const query = `query Movies($name: String, $limit: Int) {
Movies(where: { AND: [{ name: { equals: $name } }] }, limit: $limit) {
docs {
id
name
year
runtime
releaseDate
actors {
id
name
birthname
birthdate
birthplace
}
storyline
}
limit
offset
totalDocs
totalPages
}
}
`
const res = await fetch('/api/graphql', {
method: 'POST'
body: {
query,
variables: {
name: 'Happy Gilmore',
limit: 1
}
}
})
const movies = res.json();
console.log(movies);
Response:
Movies query GraphQL response
{
"data": {
"Movies": {
"docs": [
{
"id": "67f6f3f4dde9aad969739142",
"name": "Happy Gilmore",
"year": 1996,
"runtime": 92,
"releaseDate": "1996-02-16T08:00:00.000Z",
"actors": [
{
"id": "67f6f3f4dde9aad969738e68",
"name": "Adam Sandler",
"birthname": "Adam Richard Sandler",
"birthdate": "1966-09-09T07:00:00.000Z",
"birthplace": "New York, United States"
}
],
"storyline": " A rejected hockey player puts his skills to the golf course to save his grandmother's house."
}
],
"limit": 1,
"offset": null,
"totalDocs": 1,
"totalPages": 1
}
}
}
The response is a lot lighter since I remove some unneeded fields like the date fields, in addition to the nested actors.movies array.
Actors query with GraphQL
Now, let's do the same to the Actors query in the schema.graphql.
Actors query with GraphQL
const query = `query Actors($name: String, $limit: Int) {
Actors(where: { AND: [{ name: { equals: $name } }] }, limit: $limit) {
docs {
id
name
birthname
birthdate
birthplace
movies {
docs {
id
name
year
runtime
releaseDate
storyline
}
}
}
limit
offset
totalDocs
totalPages
}
}`
const res = await fetch('/api/graphql', {
method: 'POST'
body: {
query,
variables: {
name: 'Adam Sandler',
limit: 1
}
}
})
const actors = res.json();
console.log(actors);
Response:
Actors query GraphQL response
{
"data": {
"Actors": {
"docs": [
{
"id": "67f6f3f4dde9aad969738e68",
"name": "Adam Sandler",
"birthname": "Adam Richard Sandler",
"birthdate": "1966-09-09T07:00:00.000Z",
"birthplace": "New York, United States",
"movies": {
"docs": [
{
"id": "67f6f3f4dde9aad96973917d",
"name": "50 First Dates",
"year": 2004,
"runtime": 99,
"releaseDate": "2004-02-13T08:00:00.000Z",
"storyline": ""
},
{
"id": "67f6f3f4dde9aad969739142",
"name": "Happy Gilmore",
"year": 1996,
"runtime": 92,
"releaseDate": "1996-02-16T08:00:00.000Z",
"storyline": " A rejected hockey player puts his skills to the golf course to save his grandmother's house."
}
]
}
}
],
"limit": 10,
"offset": null,
"totalDocs": 1,
"totalPages": 1
}
}
}
By omitting the dates fields and nested movies.actors arrays, this query is much more streamlined.
Using GraphQL can fully optimize queries in so many ways.
For more information on how to optimize the GraphQL experience in Payload, here's a more in-depth article on GraphQL Optimization in Payload CMS
In Conclusion
So we've see how to use the join field with some realistic examples and also, how to query on joins in a couple different ways.
Using a join field is very useful but it's not always necessary. So thinking ahead is going to be key in optimizing performance as your site grows.
Also, it's important to think about how the data will be retrieved with the following considerations:
- If using REST, it's best to query by ID or a reasonable pagination limit.
- Use GraphQL when possible.
I hope this article has provided a better understanding of how to use the join field.